Recently, Assistant Professor Ji Qi Shi from the Intelligence Science and Technology School of Nanjing University, in collaboration with researchers from the Hong Kong University of Science and Technology, Chang'an University, and other institutions, proposed a semantic scene graph registration method with strong generalization capabilities, which can be widely applied in multi-agent SLAM (Simultaneous Localization and Mapping) tasks. This method aims to solve the problem of efficient alignment between maps in different subjects or multiple task executions, breaking through the key bottleneck of traditional semantic SLAM systems that rely heavily on explicit semantic descriptors and are difficult to generalize in real-world scenarios.
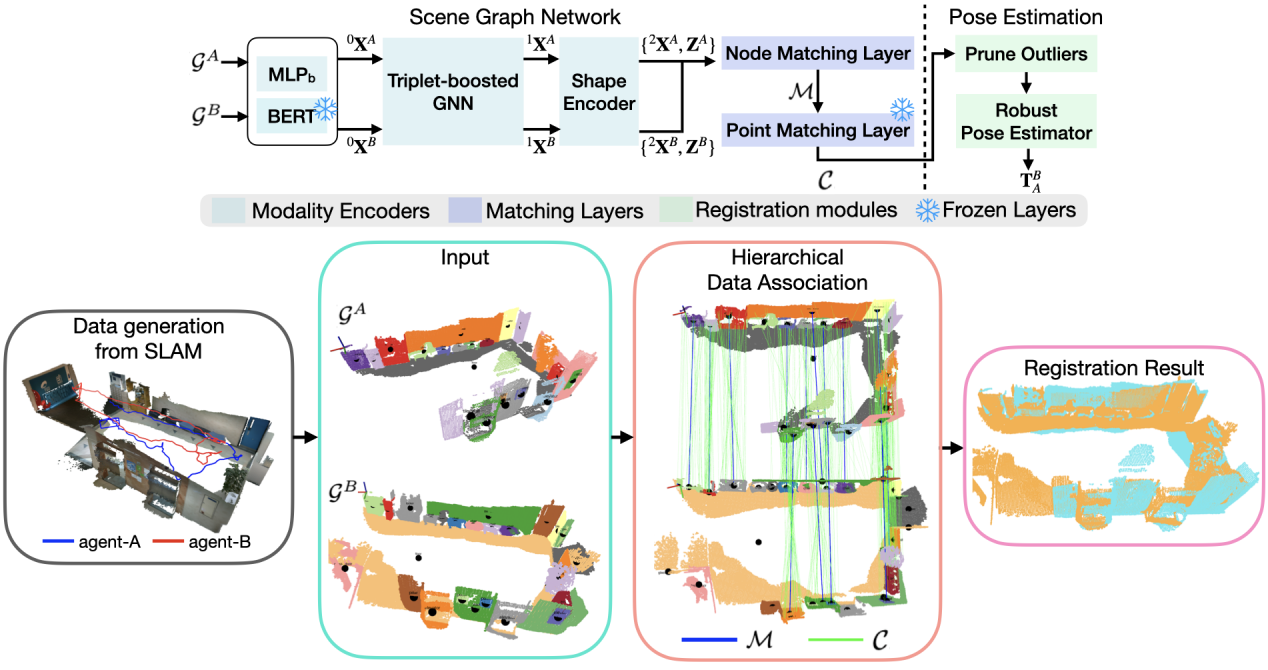
Figure 1: Flowchart and effect illustration of the method proposed by the team
The research team designed a novel scene graph neural network, SG-Reg, which integrates the encoding of three semantic graph node modalities: open set semantic features, spatially-aware local topological structure, and shape features.The research team designed a novel scene graph neural network, SG-Reg, which integrates the encoding of three semantic graph node modalities: open set semantic features, spatially-aware local topological structure, and shape features. Through the collaborative modeling of coarse-grained node representations and dense point cloud features, SG-Reg can effectively describe highly complex indoor scenes and support a coarse-to-fine registration strategy, while significantly reducing the data communication bandwidth between multi-machine systems. Through the collaborative modeling of coarse-grained node representation and dense point cloud features, SG-Reg can effectively describe highly complex indoor scenes and support a coarse-to-fine registration strategy, while significantly reducing the data communication bandwidth between multi-machine systems. To reduce the reliance on high-quality semantic annotation data, the research team combined the visual foundation large model with the self-developed semantic graph module, FM-Fusion, to automatically generate semantic scene graphs, achieving an all-self-supervised training process without the need for manual semantic annotation. To reduce reliance on high-quality semantic annotation data, the research team combined a visual foundation large model with their self-developed semantic graph module, FM-Fusion, to automatically generate semantic scene graphs, achieving an all-self-supervised training process without the need for manual semantic annotation. This self-supervised strategy not only reduces the algorithm's transfer cost but also significantly improves the system's generalization ability in real environments. This self-supervised strategy not only reduces the algorithm's transfer cost but also significantly improves the system's generalization ability in real environments.
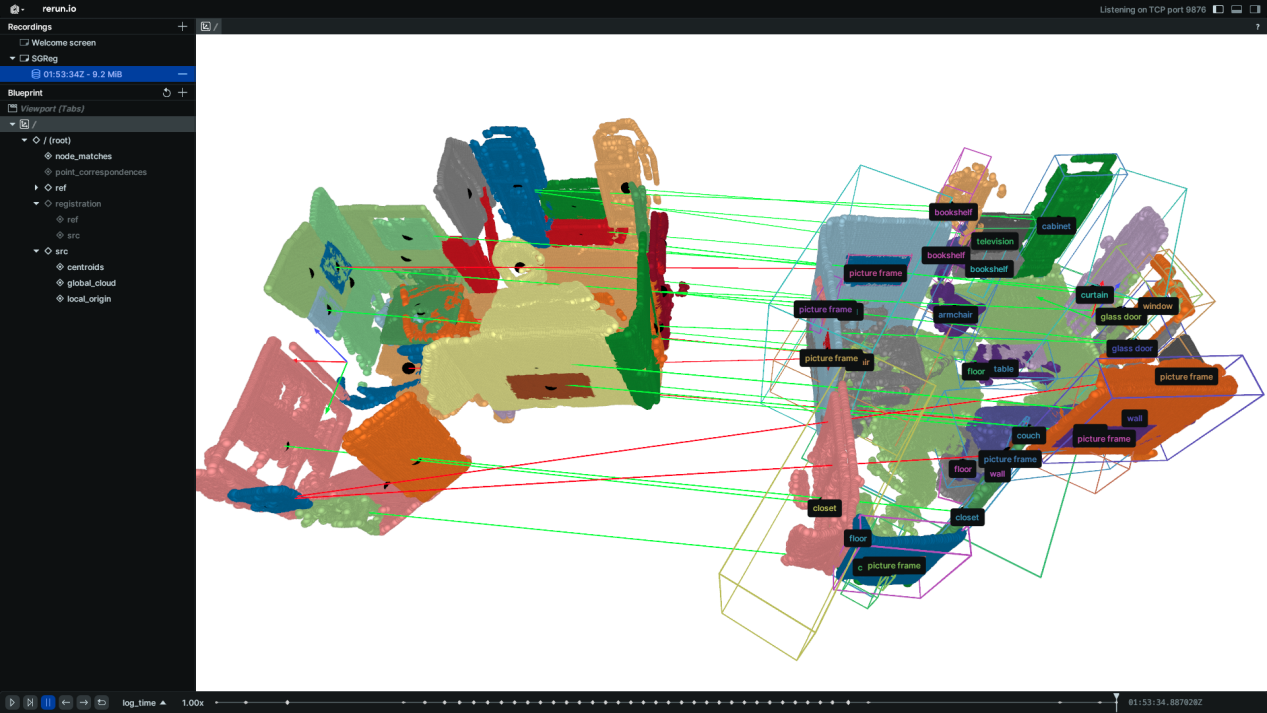
Figure 2: The actual operation effect diagram of the proposed method
The experimental results show that this method demonstrates excellent adaptability and generalizability in various real and simulated scenarios, providing effective technical support for the next generation of multi-agent collaborative perception and spatial understanding. The research team also pointed out that the current method still has room for improvement in handling large-scale architectural environments and high-noise semantic mapping. In the future, the model's scale adaptability and mapping robustness will be further expanded, promoting the reliable deployment and application of embodied intelligent systems in complex environments. This method was published in the IEEE T-RO journal.
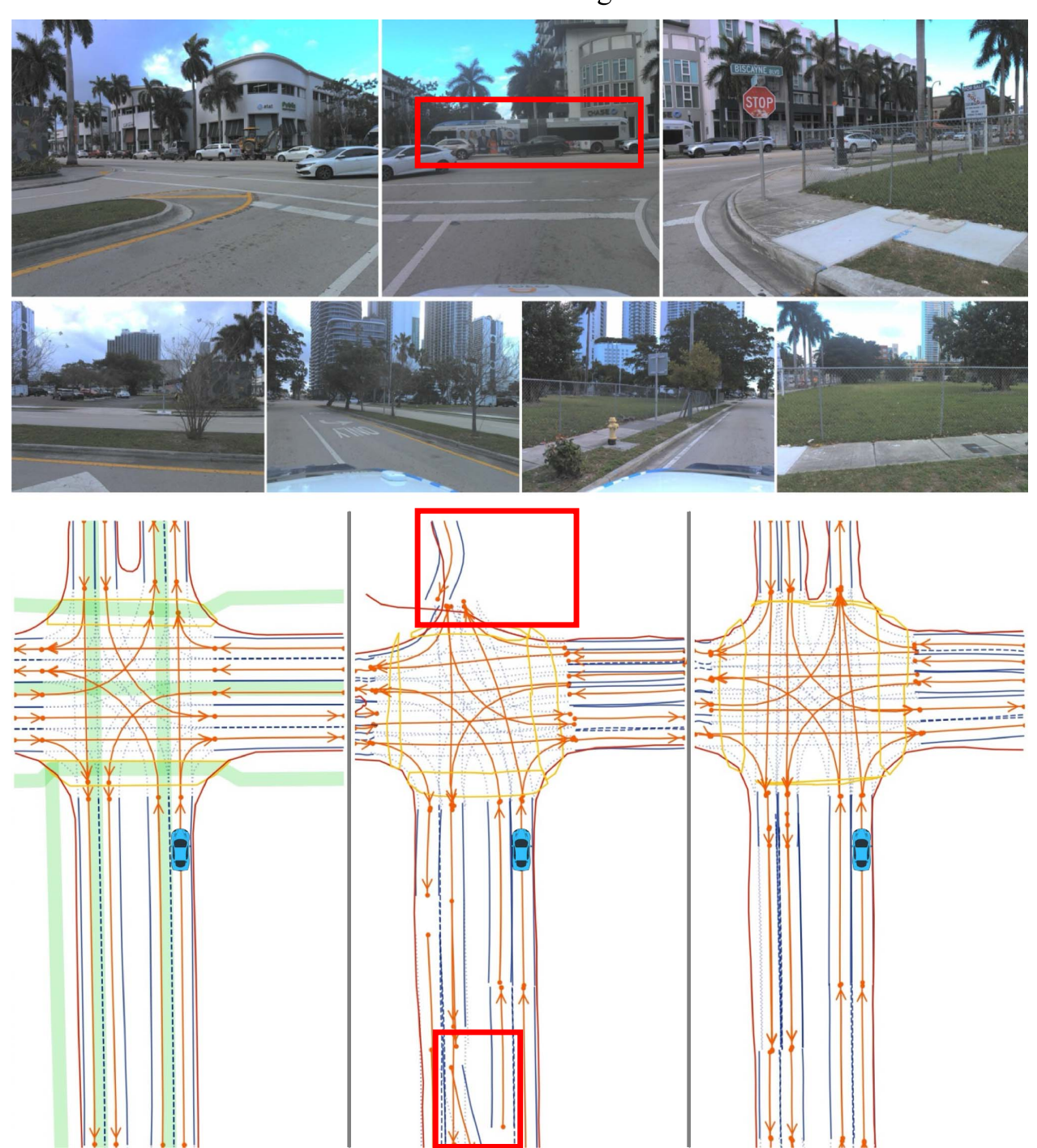
Furthermore, for the autonomous driving scenario, in order to overcome the inherent limitations of on-board sensors and complete the reconstruction of high-precision maps in long-distance or obstructed scenarios, Professor Gao Yang, Assistant Professor Shi Jieqi, and the team from the Hong Kong University of Science and Technology collaborated to propose a Scene Perception and Topology Reasoning (SEPT) framework with enhanced standard clarity (SD) maps. They explored how to effectively integrate SD maps as prior knowledge into the existing perception and reasoning processes.
The research team developed a novel hybrid feature fusion strategy, which combines SD maps and bird's-eye view (BEV) features, while taking into account both rasterized and vectorized map representation methods. The aim was to alleviate the potential misalignment issues between the feature spaces of SD maps and BEV. The research team further utilized the characteristics of SD maps to design a cross-modal perception key point detection task, which further enhanced the overall scene understanding performance.
The experimental results on the large-scale OpenLane-V2 dataset show that by effectively integrating the prior knowledge of SD maps, this framework significantly improves the performance of scene perception and topological reasoning, and can be used as a general fusion method to enhance the accuracy of existing methods. This method was published in the IEEE RA-L journal.