Tabular data is an important data type in the field of machine learning and is widely applied in real-world scenarios such as finance, healthcare, and recommendation systems. Traditional machine learning for tabular data typically assumes that the training and testing data come from a closed environment, where various learning factors remain unchanged. However, in practical applications, tabular data often exists in an open environment, facing challenges such as changes in data distribution and feature shifts. These challenges can lead to a significant decline in model performance and robustness, thereby limiting their practical application value.
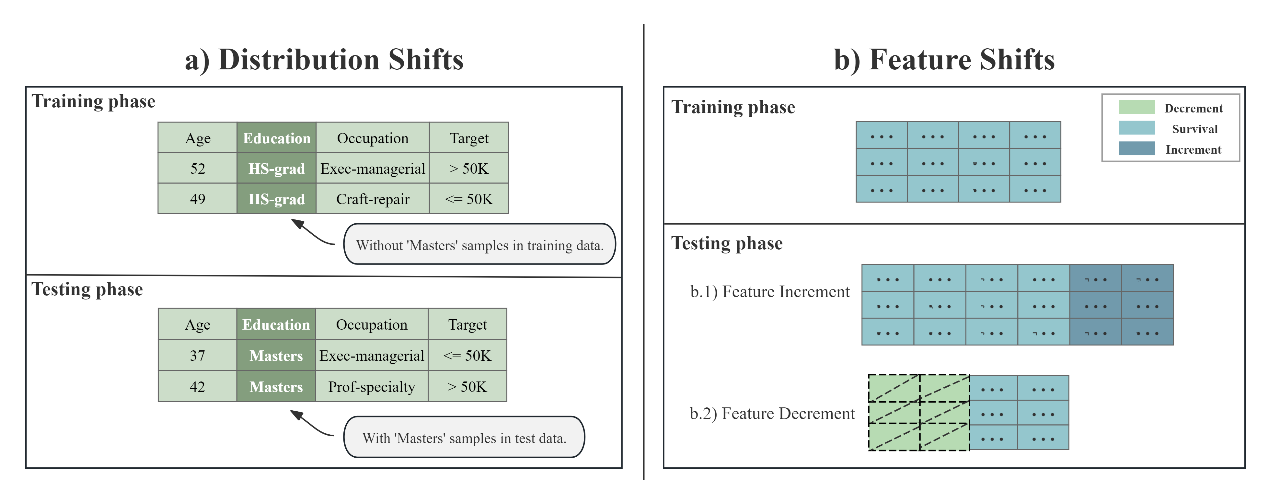
Figure 1: Common Challenges in Table Machine Learning in Open Environments
To address these issues, a research team led by Professor Guo Lanze from the School of Intelligent Science and Technology at Nanjing University has conducted in-depth research on the various challenges that tabular data machine learning may face in open environments and proposed a series of innovative methods. The relevant work has been published in top-tier academic conferences in the field, such as AAAI, IJCAI, and ICML.
Work 1: Full Test-Time Adaptation for Tabular Data Distribution Shifts (AAAI 2024)
Distribution shift is a common challenge in open environments, referring to the differences in data distribution between training and testing data. These differences may arise from covariate shift or label shift, leading to a significant decline in model performance during the testing phase. To address this challenge, the Fully Test-time Adaptation (FTTA) algorithm adjusts the pre-trained model using test data to adapt to the distribution changes in the test phase. However, existing FTTA algorithms are mainly designed for image data and have poor applicability to tabular data.
To solve this problem, a research team led by Professor Guo Lanze from the School of Intelligent Science and Technology at Nanjing University proposed the Fully Test-time Adaptation for Tabular data (FTAT) algorithm. This algorithm consists of three key modules: the Confidence Distribution Optimizer, the Local Consistency Weighter, and the Dynamic Model Ensemble, which address label shift, covariate shift, and model adaptation sensitivity, respectively. Experimental results show that the FTAT method significantly outperforms existing FTTA methods on six benchmark datasets, providing an effective solution for test-time adaptation to distribution shifts in tabular data. This work has been accepted and published at the top artificial intelligence conference AAAI 2024.
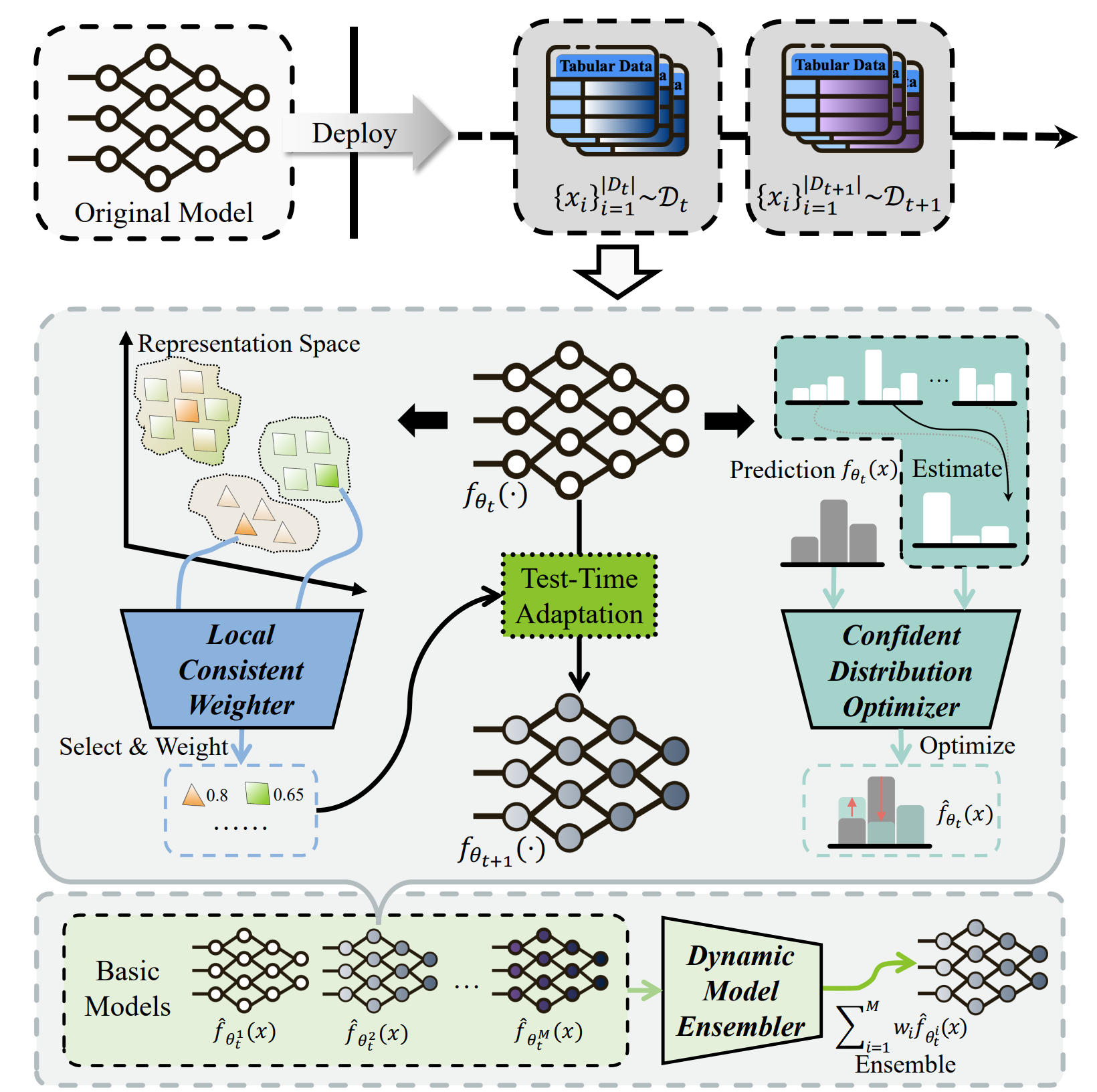
Figure 2: Schematic Diagram of the FTAT Algorithm Structure
Paper Link:https://arxiv.org/abs/2412.10871
Project Homepage:https://zhouz.dev/FTTA/
Work 2: Full Test-Time Adaptation for Tabular Data with Feature Reduction (IJCAI 2025)
Existing FTTA algorithms mostly focus on addressing distribution shifts, assuming that the feature space remains consistent between the training and testing phases. They fail to effectively tackle the challenge of feature reduction in tabular data. Feature reduction refers to the situation where the feature dimensionality in the testing phase is lower than that in the training phase. Current solutions mainly include missing feature imputation and missing feature adaptation. However, these methods have limitations in the FTTA context, such as imputation methods relying on training data and adaptation methods suffering significant performance drops when the degree of feature reduction is high.
To address this issue, a research team led by Professor Guo Lanze from the School of Intelligent Science and Technology at Nanjing University proposed two methods: LLM-IMPUTE and ATLLM. LLM-IMPUTE leverages Large Language Models (LLMs) to generate imputation values for missing features without relying on training data. ATLLM, on the other hand, constructs an augmented training module by simulating feature reduction scenarios, thereby enhancing the model's robustness during the testing phase. Experimental results show that these two methods significantly improve the performance and robustness of FTTA algorithms in scenarios with feature reduction. This work has been accepted by the top artificial intelligence conference IJCAI 2025.
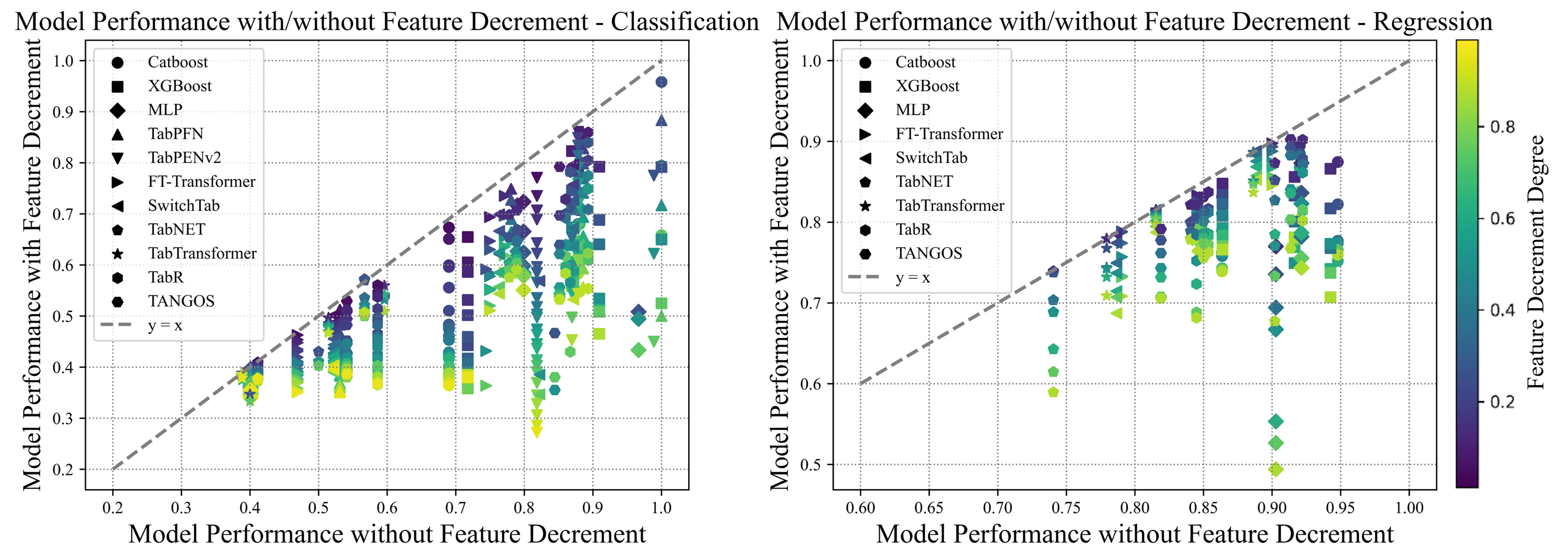
Figure 3: The Degree of Model Performance Decline is Related to the Number of Reduced Features
Work 3: Benchmark for Evaluating Feature Shifts in Tabular Data (ICML 2025)
Feature shift is another common challenge in open environments. It refers to the dynamic changes in the available feature set for the same task due to temporal evolution or spatial variation, which includes both feature reduction and feature addition. For example, in weather forecasting tasks, key sensors may stop working due to failure or aging, or they may be replaced by new sensors due to technological upgrades, leading to changes in the available features. Such changes not only disrupt the consistency of model input features but can also significantly degrade model performance and robustness.
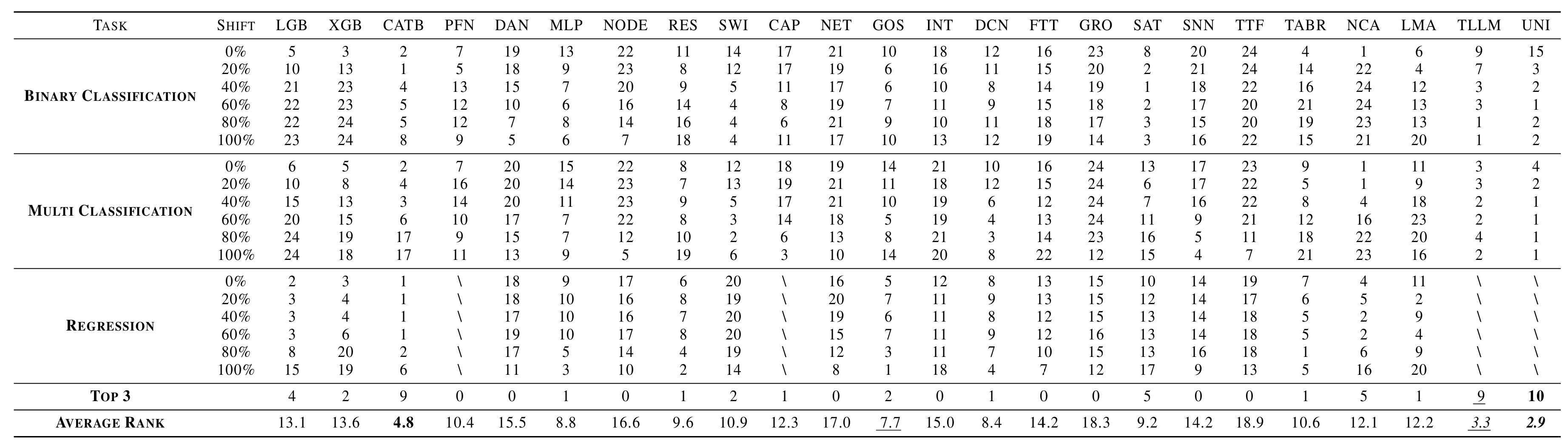
However, research on feature shifts is relatively limited, and there is a lack of high-quality benchmarks for evaluating the challenge of feature shifts. To address this issue, a research team led by Professor Guo Lanze from the School of Intelligent Science and Technology at Nanjing University conducted the first comprehensive study on feature shifts in tabular data and proposed the first tabular feature shift benchmark, TabFSBench. TabFSBench evaluates the impact of four different feature shift scenarios on four types of tabular models and, for the first time in a tabular benchmark, assesses the performance of Large Language Models (LLMs) and tabular LLMs. The study yielded three main observations: (1) Most structured models have limited applicability in feature shift scenarios; (2) The importance of shifted features is linearly related to the decline in model performance; (3) Model performance in closed environments is positively correlated with performance in feature shift scenarios. This work has been accepted and published at the top machine learning conference ICML 2025.
表4 模型处理不同表格任务的性能排名
Paper Link:https://icml.cc/virtual/2025/poster/44787
Project Homepage:https://github.com/LAMDASZ-ML/TabFSBench