表格数据是机器学习领域的重要数据类型,广泛应用于金融、医疗、推荐系统等现实场景。传统的表格数据机器学习通常假设训练和测试数据来自封闭环境,各类学习因素没有发生变化。然而在实际应用中,表格数据往往处于开放环境,面临着如数据分布变化和特征偏移等挑战。这些挑战会导致模型性能和鲁棒性显著下降,限制了它们的实际应用价值。
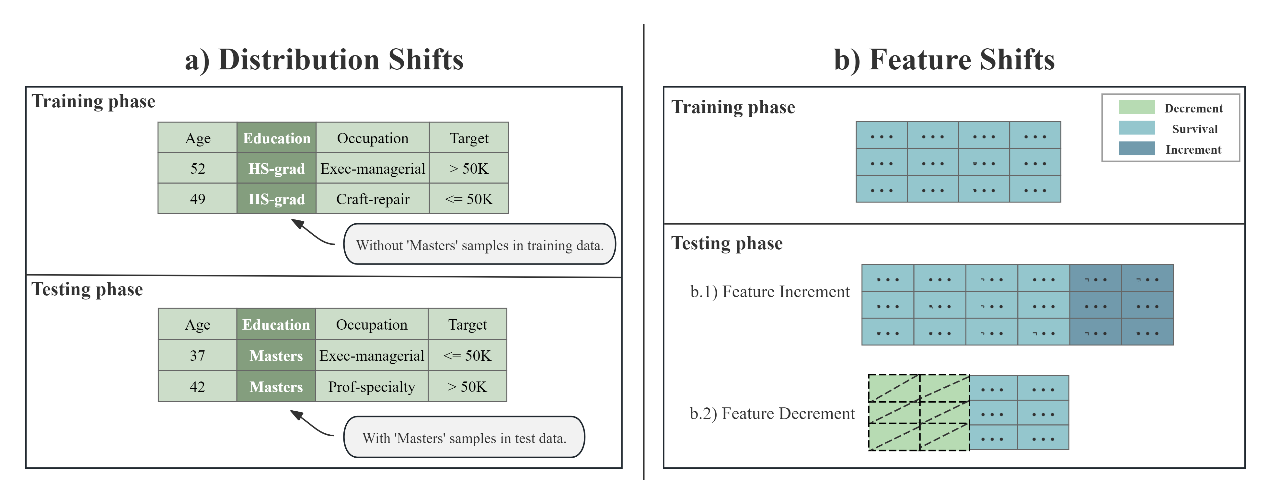
图1 开放环境表格机器学习常见挑战
为此,菠菜担保平台郭兰哲老师团队针对表格数据机器学习在开放环境下可能面临的各类挑战展开深入研究,提出了一系列创新方法,相关工作发表于AAAI、IJCAI、ICML等领域一流学术会议中。
工作一:面向表格数据分布变化的完全测试时适应(AAAI 2024)
分布变化是开放环境下的一个常见挑战,其指训练数据与测试数据在数据分布上存在差异,这种差异可能源于协变量分布变化或者标签分布变化,导致模型在测试阶段的性能显著下降。为了解决这一挑战,完全测试时适应算法(Fully Test-time Adaptation,FTTA)通过利用测试数据对预训练模型进行调整,以适应测试阶段的数据分布变化。然而,现有的FTTA算法主要针对图像数据设计,对表格数据的适用性较差。为了解决这一问题,菠菜担保平台郭兰哲老师团队提出了FTAT(Fully Test-time Adaptation for Tabular data)算法。该算法通过三个关键模块——置信分布优化器、局部一致性加权器和动态模型集成器,分别解决了标签分布变化、协变量分布变化以及模型适应性敏感性的问题。实验结果表明,FTAT方法在六个基准数据集上显著优于现有的FTTA方法,为表格数据分布变化的测试时适应问题提供了有效的解决方案。该工作已被人工智能顶级会议AAAI 2024接收发表。
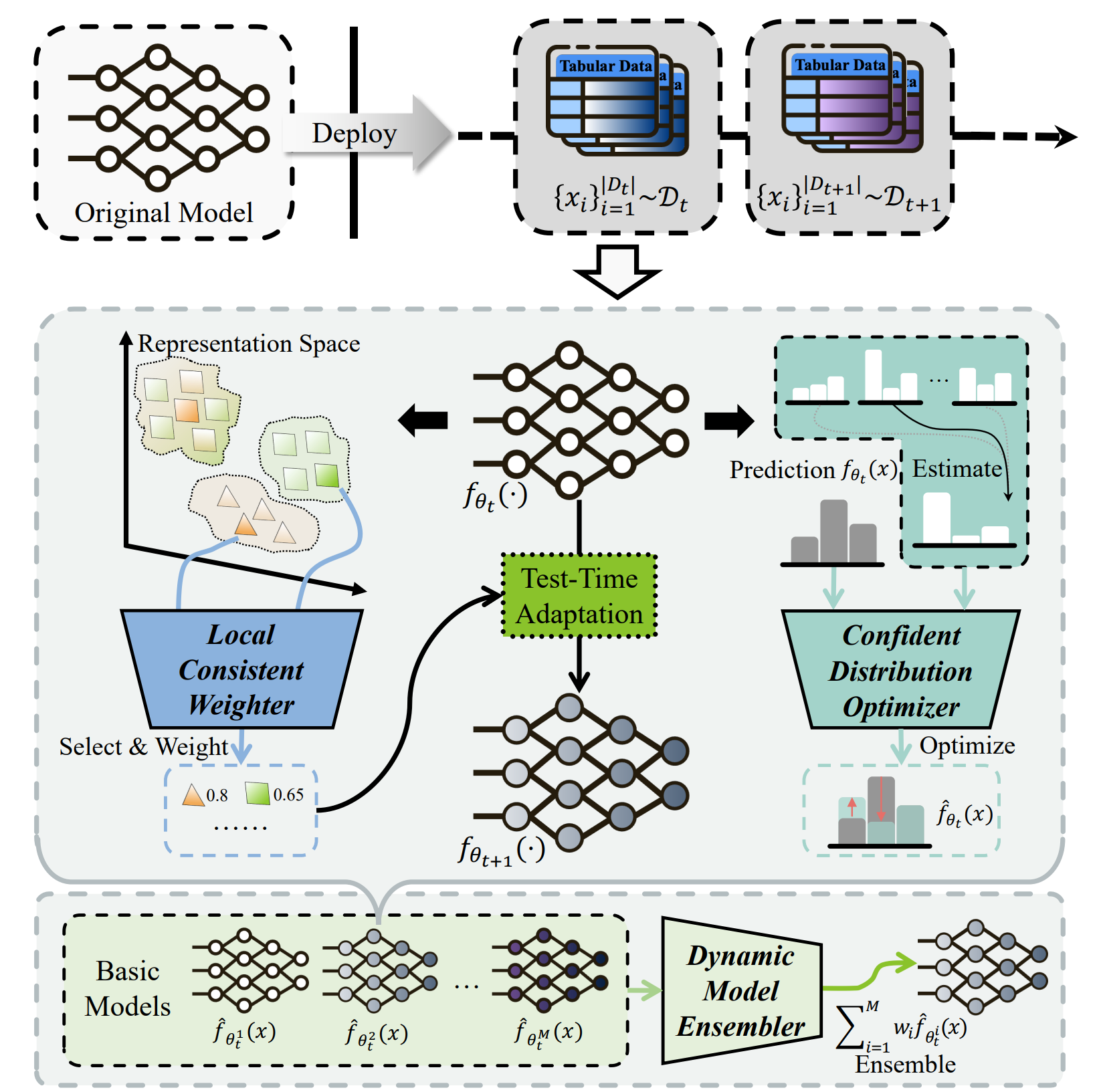
图2 FTAT算法结构示意图
论文链接:https://arxiv.org/abs/2412.10871
工作二:面向表格数据特征减少的完全测试时适应(IJCAI 2025)
现有的FTTA算法大多专注于解决分布变化问题,假设训练和测试阶段的特征空间一致,未能有效应对表格数据中特征减少挑战。特征减少是指测试阶段的特征维度较训练阶段减少,当前的解决方法主要包括缺失特征插补和缺失特征适应,但这些方法在FTTA场景中均存在插补方法依赖训练数据,适应方法在特征减少程度较高时性能显著下降等局限性。为了解决这一问题,菠菜担保平台郭兰哲老师团队提出了LLM-IMPUTE和ATLLM两种方法。LLM-IMPUTE利用大语言模型(Large Language Models, LLMs)在无需训练数据的情况下生成缺失特征的插补值,ATLLM则通过模拟特征减少场景构造增强训练模块,从而提升模型在测试阶段的鲁棒性。实验结果表明,这两种方法显著提高了FTTA算法在特征减少场景中的性能和鲁棒性。该工作已被人工智能顶级会议IJCAI 2025接收。
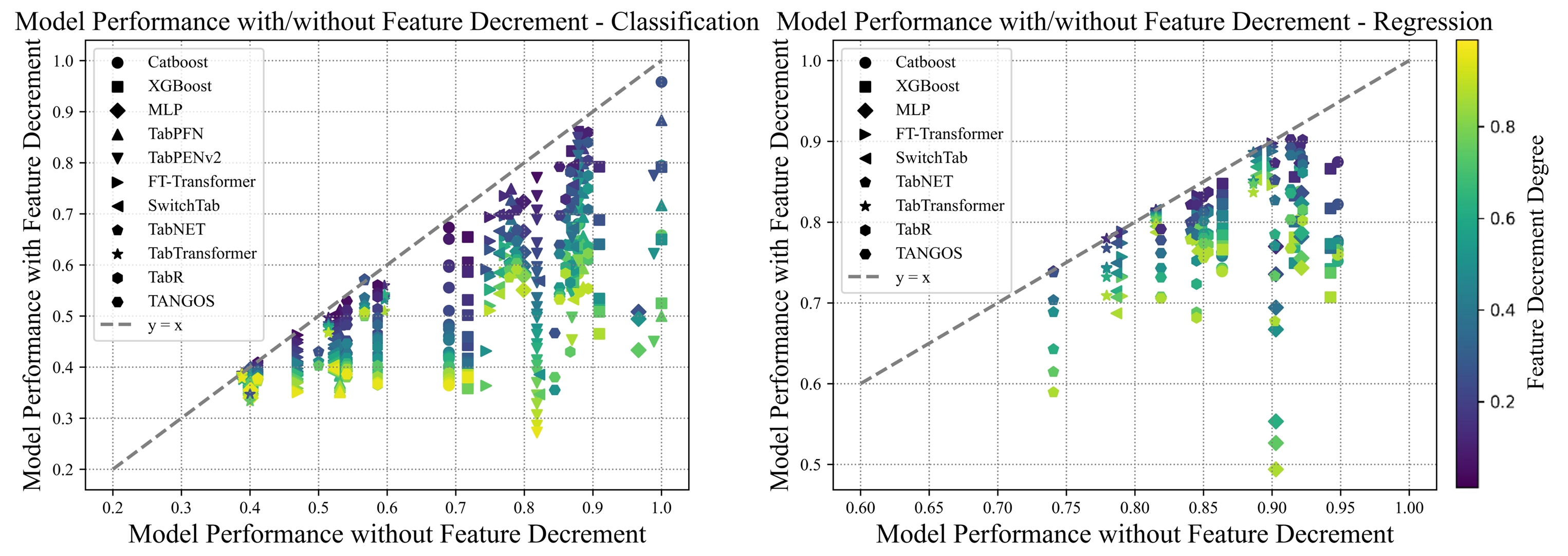
图3 模型性能下降程度与减少的特征数量有关
工作三:面向表格数据特征偏移的评测基准(ICML 2025)
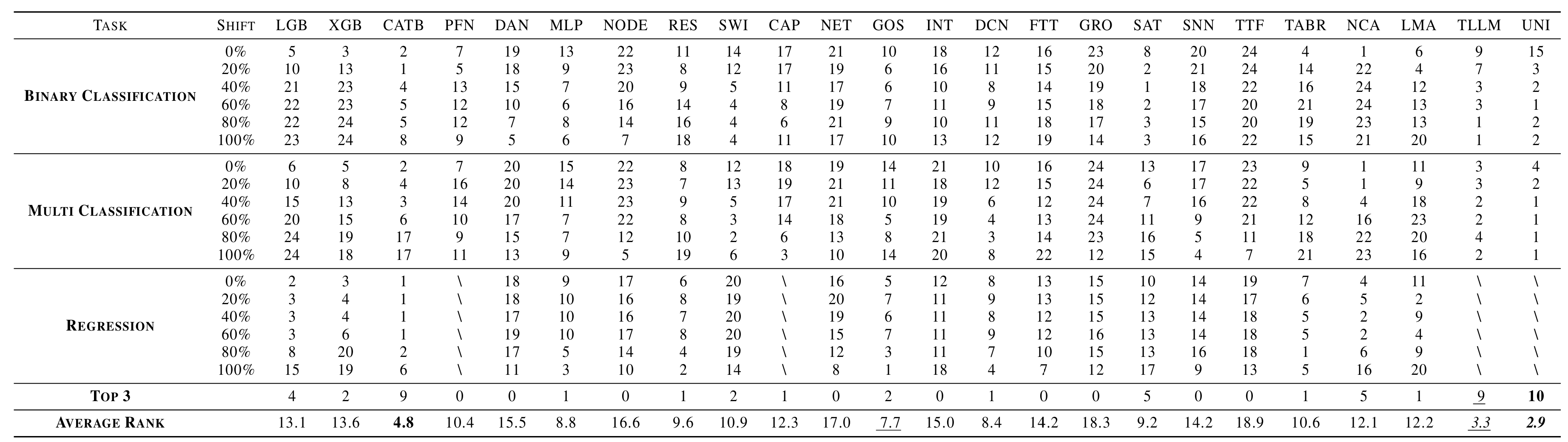
特征偏移是开放环境中另一个普遍存在的常见挑战,其指的是由于时间演化或空间变化,同一任务的可获取特征集发生动态变化的现象,包含特征减少和特征增加两种情况。例如,在天气预报任务中,关键传感器可能因故障或老化而停止工作,也可能因技术升级而被新传感器取代,从而导致可获取的特征发生变化。这种变化不仅会破坏模型输入特征的一致性,还可能显著降低模型的性能和鲁棒性。然而,有关特征偏移的研究相对有限,而且缺乏针对特征偏移挑战的高质量评测基准。为了解决这一问题,菠菜担保平台郭兰哲老师团队首次对表格数据中的特征偏移进行了全面研究,并提出了第一个表格特征偏移基准测试TabFSBench。TabFSBench评估了四种不同特征偏移场景对四类表格模型的影响,并首次在表格基准测试中评估了LLMs和表格LLMs的性能。研究得出了三个主要观察结果:(1)大多数结构化模型在特征偏移场景下的适用性有限;(2)偏移特征的重要性与模型性能下降呈线性关系;(3)模型在封闭环境中的性能与其在特征偏移场景下的性能正相关。该工作已被机器学习顶级会议ICML 2025接收发表。
表4 模型处理不同表格任务的性能排名
论文链接:https://icml.cc/virtual/2025/poster/44787
项目主页:https://github.com/LAMDASZ-ML/TabFSBench